Unlocking the power of unstructured data for AI


In today’s digital age, most people — aside from a select group of software engineers, data scientists, and business analysts — prefer consuming information in formats that feel intuitive and human-readable but are inherently unstructured for machines. Formats like PDFs, scanned documents, and freeform text often appear well-organized to someone with a non-tech background. However, studies show that unstructured data now makes up around 80% of all data within enterprises, a figure that has surged with the rapid growth of digital content. For those working to leverage machine learning models, this prevalence of unstructured data presents a formidable challenge, as these formats lack the structure which organizations require for a seamless analysis and processing.
With the rapid advancements in AI and Large Language Models (LLMs), this challenge can now be effectively addressed for certain types of documents that retain some inherent structure. Examples include invoices, quotations, sales reports, bank statements, and similar semi-structured formats.
Structured data is the backbone of modern analytics and automation. It fuels dashboards, machine learning pipelines, and AI-driven insights that empower organizations to make data-backed decisions. However, converting unstructured formats into structured data has traditionally been a labor-intensive process, requiring manual intervention or the use of rule-based tools that struggle with diverse layouts and contextual variability.
At DataGOL, we are at the forefront of this transformation, leveraging cutting-edge AI and LLM technologies to simplify and automate the data extraction process. Our solutions are designed to seamlessly handle semi-structured documents, enabling businesses to extract insights with precision and efficiency. Whether it’s extracting financial details from invoices, consolidating data from sales reports, or processing large volumes of bank statements, DataGol provides the tools and expertise to make the transition from unstructured to structured data effortless.
LLMs offer a transformative solution to these challenges. Unlike traditional systems, which rely on rigid rules or pre-defined templates, LLMs excel at understanding the semantics and context within documents. At DataGol, we integrate these advanced capabilities into our platform, enabling our clients to process diverse document formats and extract structured insights that drive smarter decisions.
For example, consider the process of extracting financial details from invoices or consolidating data from multiple sales reports. While traditional approaches falter when faced with variations in layout or terminology, LLMs, combined with DataGOL’s expertise, adapt to these changes, offering a level of flexibility previously unattainable. By leveraging pre-trained LLMs or fine-tuning them for domain-specific tasks, we help businesses automate at scale, dramatically reducing time and effort.
At DataGOL, we handle both structured and unstructured data, making our platform a powerful hub for transforming and leveraging information. The Data Extraction Copilot operates through a meticulously designed pipeline, ensuring seamless processing of unstructured documents. We have fine-tuned the data extraction process to deliver unparalleled accuracy and efficiency. Let’s dive into the key components of this copilot and explore how our platform has mastered the art of data extraction.
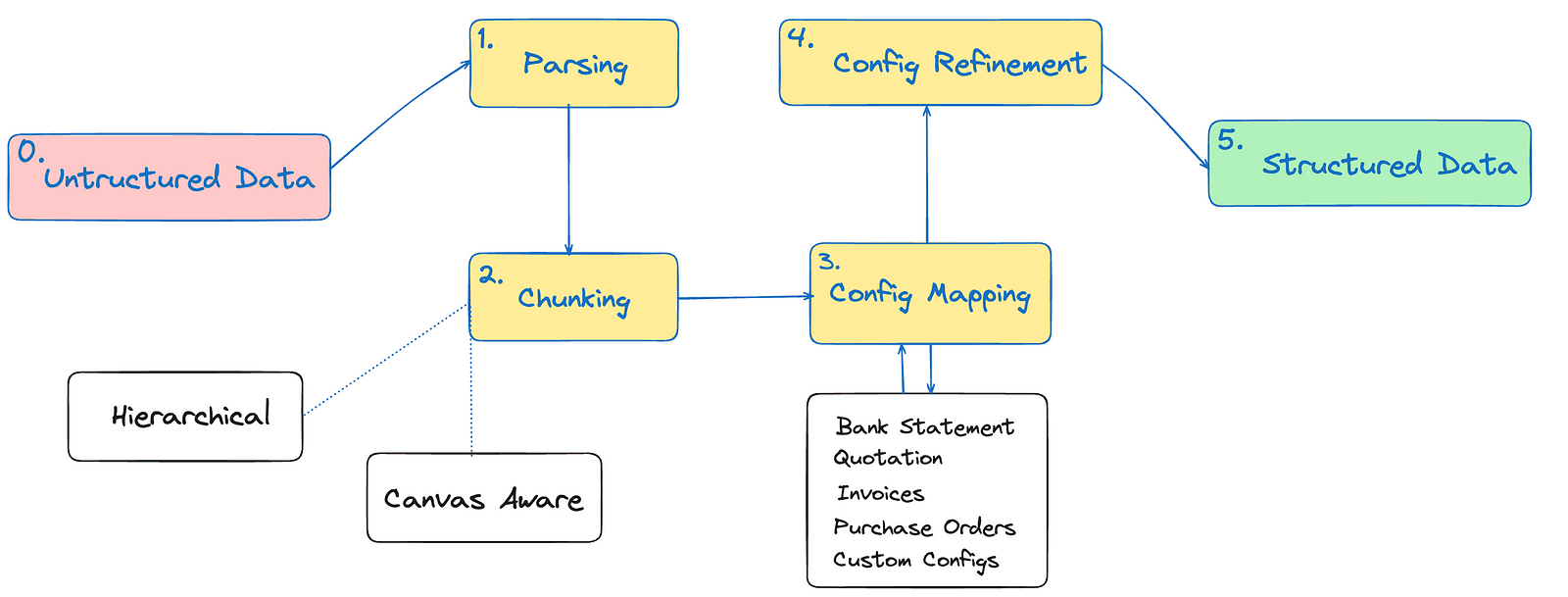
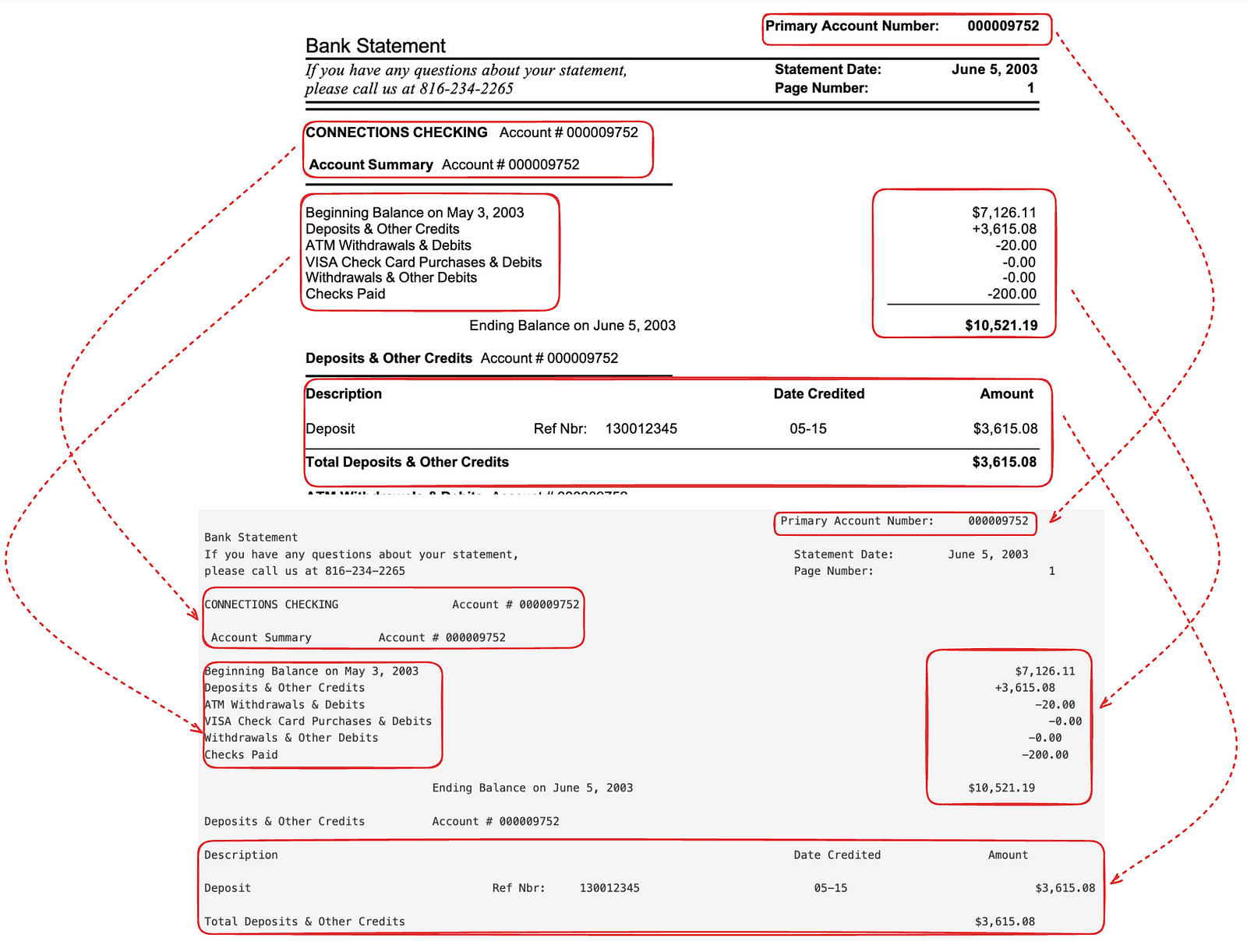
The parsers form the first and foundational stage of the pipeline, aptly referred to as the ingestion stage. Their primary role is to handle raw input data, whether in the form of PDFs, scanned documents, images, or other unstructured formats. This stage is critical because its accuracy directly impacts the downstream stages. Our parsers are designed to handle a diverse range of formats, ensuring broad compatibility and robust performance. We extract key attributes such as document type, structure, and other metadata that guides subsequent processing stages. By leveraging AI-driven parsers that can intelligently read, segment, and preprocess text, tables, and images from documents.
Following the ingestion stage, the pipeline proceeds to chunking, a critical process that organizes parsed data into meaningful segments. After extensive exploration of emerging chunking methodologies, our team adopted the best practices to implement two robust chunking techniques.
Hierarchical Chunking preserves the relationships among titles, subtitles, paragraphs, and other structural elements. This method groups related components — such as bullet points within a list or cells within a table — into cohesive document objects, ensuring that their contextual integrity remains intact.
Canvas-Aware Chunking, on the other hand, captures the document’s layout and structure by converting it into a markdown format, effectively representing the visual arrangement of content. Combined with OCR for handling scanned or image-based documents, these techniques excel in structuring diverse document types. Together, they provide superior results, ensuring the extracted data retains both its logical flow and visual representation.
Once the document is chunked, it moves to the configuration mapping stage, where it is matched to one of many carefully crafted configurations designed to handle diverse document types and layouts. These configurations act as blueprints, defining how the extracted data is structured and interpreted. To bridge any gaps in our default configurations, we work closely with customers, ensuring their unique requirements are met and making them an active part of the process. This collaborative approach not only customizes the pipeline to their needs but also fosters trust and inclusivity. By continuously refining these configurations and adapting them to new formats, we ensure that each document is mapped accurately and consistently, laying the foundation for smooth data structuring in the later stages of the pipeline.

At this stage, users have the opportunity to refine the predefined configuration, ensuring that the AI focuses exclusively on information relevant to their specific document. This step is particularly valuable for accommodating variations across document types. For instance, some invoices may display taxes in an additive manner with a detailed breakdown, while others include taxes within the final cost without explicit separation. By enabling users to modify configurations, the pipeline becomes adaptable to these nuances, ensuring accurate data extraction tailored to the document’s context. This flexibility not only enhances the relevance of the structured output but also ensures that the extracted data aligns seamlessly with the user’s needs and expectations for further AI-driven processing.
Finally, the pipeline reaches its culmination, where the entire document is processed based on the selected and refined configuration. This is the stage where the magic happens — the unstructured data is transformed into meaningful and accessible formats. The output is delivered in two of the most prominent structured formats: tables, for tabular representation of data, and JSON, for hierarchical and machine-readable data structuring. These formats ensure seamless integration into downstream AI/ML workflows, enabling analytics, automation, and decision-making with unparalleled efficiency. The combination of precision, adaptability, and collaboration in earlier stages guarantees that the extracted data meets the highest standards of accuracy and relevance.

As AI continues to evolve, the potential for automated data extraction extends beyond semi-structured formats. Emerging multimodal models, capable of processing both text and visual information, promise even greater accuracy in handling complex documents with charts, images, or nested tables. With DataGOL at the helm of these innovations, we’re unlocking a future where the barriers between unstructured and structured data are further eroded, enabling our clients to achieve unparalleled efficiency and insight.

Author
Shivam Bhagwani
Software Engineer at DataGOL


